Java의 정석 : 3rd Edition, 2016을 개인 학습용으로 정리한 내용입니다.
"ppt 파일 자료, 연습문제"를 학습 용도로 배포할 수 있음을 고지하셨습니다.
저자님께 감사드립니다.
[11-1] 다음은 정수집합 1, 2, 3, 4와 3, 4, 5, 6의 교집합, 차집합, 합집합을 구하는 코드이다.
코드를 완성하여 실행결과와 같은 결과를 출력하시오.
[Hint] ArrayList클래스의 addAll(), removeAll(), retainAll()을 사용하라.
import java.util.*;
class Exercise11_1 {
public static void main(String[] args) {
ArrayList list1 = new ArrayList();
ArrayList list2 = new ArrayList();
ArrayList kyo = new ArrayList(); // 교집합
ArrayList cha = new ArrayList(); // 차집합
ArrayList hap = new ArrayList(); // 합집합
list1.add(1);
list1.add(2);
list1.add(3);
list1.add(4);
list2.add(3);
list2.add(4);
list2.add(5);
list2.add(6);
// (1) 알맞은 코드를 넣어 완성하시오.
System.out.println("list1 = " + list1);
System.out.println("list2 = " + list2);
System.out.println("kyo = " + kyo);
System.out.println("cha = " + cha);
System.out.println("hap = " + hap);
}
}
// list1 = [1, 2, 3, 4]
// list2 = [3, 4, 5, 6]
// kyo = [3, 4]
// cha = [1, 2]
// hap = [1, 2, 3, 4, 5, 6]
나의 답 :
// 교집합(A ∩ B) : 집합 A와 B의 공통 요소들로 이뤄진 집합
kyo.addAll(list1); // list1의 모든 요소를 kyo에 저장
kyo.retainAll(list2); // kyo에 저장된 요소들 중 list2와 공통된 요소만 남기고 나머지는 삭제
// 차집합(A - B) : 집합 A에 대해 B의 요소를 포함하지 않는 집합
cha.addAll(list1); // list1의 모든 요소를 cha에 저장
cha.removeAll(list2); // cha에 저장된 요소들 중 list2와 공통된 요소들을 모두 제거
// 합집합(A ∪ B) : 집합 A와 B의 요소들을 포함하는 집합(중복 X)
hap.addAll(list1); // list1의 모든 요소를 hap에 저장
hap.removeAll(list2); // hap에 저장된 요소들 중 list2와 공통된 요소들을 모두 제거(중복 제거)
hap.addAll(list2); // list2의 모든 요소를 hap에 저장1) boolean addAll(Collection c) : 주어진 컬렉션의 모든 객체를 저장한다.
2) boolean retainAll(Collection c) : 저장된 객체 중 주어진 컬렉션과 공통된 요소만 남기고 나머지는 삭제한다.
3) boolean removeAll(Collection c) : 지정한 컬렉션에 저장된 것과 동일한 객체들을 ArrayList에서 제거한다.
ArrayList
컬렉션 프레임웍에서 가장 많이 사용되는 컬렉션 클래스(List 구현 : 순서O, 중복O)
* 배열을 이용하는 자료구조(ArrayList, Vector)
* ≒ Vector를 개선한 것(구현 원리, 기능 동일)
* Vector(동기화 O), ArrayList(동기화 X)
* 객체를 생성할 때, 실제 저장할 개수보다 약간 여유있는 크기(2배)로 생성해야 함.
* 장점 : 데이터를 읽는데 걸리는 시간(access time) 가장 빠름(순차적인 데이터 추가/삭제에 유리)
* 단점 : 크기 변경 불가(배열 기반), 비순차적인 데이터 추가/삭제에 비 효율적
해설 : kyo를 활용하는 방법
kyo.addAll(list1); // list1의 모든 요소를 kyo에 저장
kyo.retainAll(list2); // list2와 kyo의 공통 요소만 남기고 삭제
cha.addAll(list1);
cha.removeAll(list2); // cha에서 list2와 공통된 요소들을 모두 삭제
hap.addAll(list1); // list1의 모든 요소를 hap에 저장
hap.removeAll(kyo); // hap에서 kyo와 공통된 모든 요소를 삭제
hap.addAll(list2); // list2의 모든 요소를 hap에 저장
[11-2] 다음 코드의 실행결과를 적으시오.
import java.util.*;
class Exercise11_2 {
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add(3);
list.add(6);
list.add(2);
list.add(2);
list.add(2);
list.add(7);
HashSet set = new HashSet(list);
TreeSet tset = new TreeSet(set);
Stack stack = new Stack();
stack.addAll(tset);
while(!stack.empty())
System.out.println(stack.pop());
}
}
나의 답 :
import java.util.*;
class Exercise11_2 {
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add(3);
list.add(6);
list.add(2);
list.add(2);
list.add(2);
list.add(7); // 3, 6, 2, 2, 2, 7
HashSet set = new HashSet(list); // 2, 3, 6, 7
TreeSet tset = new TreeSet(set); // 2, 3, 6, 7
Stack stack = new Stack();
stack.addAll(tset); // 2, 3, 6, 7
while(!stack.empty()) // 스택이 비워질 때까지 반복문을 수행한다.
System.out.println(stack.pop()); // 7 -> 6 -> 3 -> 2
}
}1) ArrayList : (배열 기반) 데이터가 순차적으로 저장되며, 중복되는 값 저장 가능(List 구현 : 순서O, 중복O)
2) HashSet : 데이터가 순서에 상관없이 저장되며, 중복되는 값을 저장하지 않음(Set 구현 : 순서X, 중복X)
* HashSet(Collection c) : 주어진 컬렉션을 저장하는 HashSet를 생성한다.
* LinkedHashSet에 데이터를 저장하면 순차적으로 저장된다.
3) TreeSet : 데이터를 이진 탐색 트리(binary search tree) 형태로 저장(Set 구현 : 순서X, 중복X)
* 정렬 및 범위 검색에 유리하며, 반복적인 비교를 통해 데이터가 정렬된 상태로 저장된다.
* TreeSet(Collection c) : 주어진 컬렉션을 저장하는 TreeSet를 생성한다.
* 이진 트리(binary tree) : 각 요소(node)가 나무(tree)형태로 연결된 구조
* 이진 탐색 트리(binary search tree) : 부모보다 작은 값은 왼쪽, 큰 값은 오른쪽에 저장한다.
* 데이터가 순차적으로 저장되는게 아니라서 저장되는 순서를 보장하지 않는다.
4) Stack : 가장 기본적인 자료 구조(Stack, Queue)
* 마지막에 저장한 데이터를 가장 먼저 꺼내는 LIFO(Last In First Out) 구조이다.
* 자료 구조(Data Structure) : 자료(데이터)를 저장, 조직, 관리하는 방법
4-1) boolean addAll(Collection c) : 주어진 컬렉션의 모든 객체를 Stack에 저장한다.
4-2) boolean empty() : Stack이 비어있는지 확인(비어있다면 true를 그렇지 않으면 false를 반환)
4-3) pop() : Stack의 맨 위에 저장된 객체를 꺼낸다(비어있다면 EmptyStackException예외 발생)
* pop() : 맨 위에 저장된 객체를 꺼내서 보는 것(삭제)
* peek() : 맨 위에 저장된 객체를 꺼내지 않고 보는 것(읽기)
* push() : Stack에 데이터를 넣는 작업, pop() : Stack의 데이터를 꺼내는 작업
해설 : 각 컬렉션 클래스들의 특징을 이해하고 있는지 확인하는 문제이다.
ArrayList list = new ArrayList();
list.add(3);
list.add(6);
list.add(2);
list.add(2);
list.add(2);
list.add(7); // 3, 6, 2, 2, 2, 7
HashSet set = new HashSet(list); // 2, 3, 6, 7 : 중복 요소들이 제거되고 순서가 유지되지 않음.
TreeSet tset = new TreeSet(set); // 2, 3, 6, 7 : 오름차순으로 정렬된다.
Stack stack = new Stack(); // 데이터를 Stack에 넣었다 꺼내면 저장 순서와 반대가 된다.
stack.addAll(tset); // TreeSet에 저장된 모든 요소를 Stack에 저장
while(!stack.empty()) // 스택이 비워질 때까지 반복문을 수행한다.
System.out.println(stack.pop()); // stack에 저장된 값을 하나씩 꺼낸다.
// 7
// 6
// 3
// 21) ArrayList : 중복을 허용하고 저장 순서를 유지한다.
2) HashSet : 중복을 허용하지 않기 때문에 중복 요소들은 저장되지 않는다(저장 순서를 유지하지 않음)
3) TreeSet : 요소들을 정렬해서 저장하는데, 따로 정렬 기준을 주지 않았기 때문에 기본 정렬(오름차순)로 정렬한다.
4) Stack : FILO 구조로 되어 있기 때문에 TreeSet의 모든 요소들을 저장한 다음 다시 꺼내면 저장한 순서와 반대가 된다.
[11-3] 다음 중 ArrayList에서 제일 비용이 많이 드는 작업은?
단, 작업 도중에 ArrayList의 크기 변경이 발생하지 않는다고 가정한다.
a. 첫 번째 요소 삭제
b. 마지막 요소 삭제
c. 마지막에 새로운 요소 추가
d. 중간에 새로운 요소 추가
나의 답 : d. 중간에 새로운 요소 추가
* ArrayList는 배열을 기반으로 하는 컬렉션 클래스이다.
* 배열 중간에 새로운 요소를 추가하려면 다른 요소들을 이동시켜야 한다.
* 다른 요소들을 이동시킨 후 추가해야 하므로 첫 번째 요소를 삭제하는 것보다 더 많은 비용이 발생할 줄 알았다.
해설 : a. 첫 번째 요소 삭제
a) ArrayList는 배열을 기반으로 한다.
배열은 크기를 변경할 수 없기 때문에 저장할 공간이 부족하면 새 배열을 만든 후 내용을 복사해야 한다.
배열의 첫 번째 요소를 삭제하면, 빈자리를 채우기 위해 나머지 모든 요소들을 이동시켜야 하므로 많은 비용이 든다.
d) 배열의 중간에 새로운 요소를 추가 or 삭제하는 건 다른 요소들을 이동시켜야 한다.
배열을 새로 생성하는 것보다는 적지만 역시 비용이 많이 드는 작업이다.
b, c) 마지막에 요소를 추가 or 삭제하는 건 다른 요소들을 이동시킬 필요가 없어 아주 적은 비용으로 처리 가능하다.
[11-4] LinkedList클래스는 이름과 달리 실제로는 이중 원형 연결리스트(doubly circular linked list)로 구현되어 있다.
LinkedList인스턴스를 생성하고 11개의 요소를 추가했을 때,
이 11개의 요소 중 접근시간(access time)이 가장 오래 걸리는 요소는 몇 번째 요소인가?
책과 내용이 달라 알아보니 LinkedList클래스는 이중 연결리스트(doubly linked list)로 구현되어 있다.
나의 답 : 11번째 요소(마지막 요소) 이중 연결리스트(doubly linked list) 기준
1) 이중 연결리스트(doubly linked list) 기준 : 요소를 하나하나 거쳐야 하므로 마지막 요소에 접근하는 시간이 가장 길다.
2) 이중 원형 연결리스트(doubly circular linked list) 기준 : 6번째 요소(가운데)에 접근하는 시간이 가장 길다.
* 6번째 요소와 7번째 요소의 접근 시간이 동일하다 생각할 수 있다.
1 → 2 → 3 → 4 → 5 → 6
1 → 11 → 10 → 9 → 8 → 7
* 구현 방법에 따라 다를 수 있겠지만, 일반적으로는 가장 가운데에 위치한 요소의 접근 시간이 가장 길다.
LinkedList
ArrayList(배열)의 단점을 보완하기 위해 고안된 자료 구조
* 불연속적으로 존재하는 데이터를 서로 연결한다(참조로 연결된 구조)
* 특정 요소에 바로 접근할 수 없고, 하나하나 순서대로 거쳐야 한다(doubly linked list)
* 이전 요소로 접근하기 어려움(구조 : 다음 요소의 주소, 데이터)
예) 3번째 요소 : 1번째 요소 → 2번째 요소, 2번째 요소 → 3번째 요소
doubly circular linked list(이중 원형 연결리스트)
LinkedList(단방향)의 접근성(accessibility)을 보다 향상시킨 자료 구조
* 첫 번째 요소와 마지막 요소를 서로 연결시켜 원형 형태를 갖는다.
* 이전 요소로 접근하기 용이(구조 : 다음 요소의 주소, 이전 요소의 주소, 데이터)
- 첫 번째 요소에서 마지막 요소에 접근하려면 한 번만 이동하면 된다(←)
- 마지막 요소에서 첫 번째 요소에 접근하려면 한 번만 이동하면 된다(→)
예) Tv 채널 : 마지막 채널 →(다음) 첫 번째 채널 / 마지막 채널 ←(이전) 첫 번째 채널
Q. LinkedList클래스를 doubly circular linked list로 구현하지 않은 이유?
A. 반복문으로 요소에 접근할 때 마지막 요소에서 다시 첫 번째 요소로 이동되므로 무한 루프에 빠질 수 있다.

[11-5] 다음에 제시된 Student클래스가 Comparable인터페이스를 구현하도록 변경해서 이름(name)이 기본 정렬기준이 되도록 하시오.
import java.util.*;
class Student {
String name;
int ban, no;
int kor, eng, math;
Student(String name, int ban, int no, int kor, int eng, int math) {
this.name = name;
this.ban = ban;
this.no = no;
this.kor = kor;
this.eng = eng;
this.math = math;
}
int getTotal() {
return kor + eng + math;
}
float getAverage() {
return (int)((getTotal() / 3f) * 10 + 0.5) / 10f;
}
public String toString() {
return name + ", " + ban + ", " + no + ", " + kor + ", " + eng + ", " + math
+ ", " + getTotal() + ", " + getAverage();
}
}
class Exercise11_5 {
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add(new Student("홍길동", 1, 1, 100, 100, 100));
list.add(new Student("남궁성", 1, 2, 90, 70, 80));
list.add(new Student("김자바", 1, 3, 80, 80, 90));
list.add(new Student("이자바", 1, 4, 70, 90, 70));
list.add(new Student("안자바", 1, 5, 60, 100, 80));
Collections.sort(list);
Iterator it = list.iterator();
while(it.hasNext())
System.out.println(it.next());
}
}
// 김자바, 1, 3, 80, 80, 90, 250, 83.3
// 남궁성, 1, 2, 90, 70, 80, 240, 80.0
// 안자바, 1, 5, 60, 100, 80, 240, 80.0
// 이자바, 1, 4, 70, 90, 70, 230, 76.7
// 홍길동, 1, 1, 100, 100, 100, 300, 100.0
나의 답 :
// class Student {
class Student implements Comparable {
// 생략
@Override
public int compareTo(Object o) {
if (o instanceof Student) {
Student tmp = (Student) o;
return name.compareTo(tmp.name); // String.compareTo() 호출
} else {
return -1;
}
}
}객체는 기준을 정해주지 않는 이상 어떤 객체가 더 높은 우선순위를 갖는지 판단할 수 없다.
Comparator or Comparable(interface)를 구현하여 정렬 기준을 제공해야 한다.
1) 기본 정렬 기준(오름차순)으로 정렬하기 위해 Student클래스에 Comparable를 구현한다.
2) 학생의 이름을 기준으로 정렬하기 위해 인스턴스 변수 name를 비교하도록 compareTo()를 구현한다.
2-1) compareTo(Object o)의 인자가 Object타입이므로 Student로 형변환해야 한다.
Object타입에는 인스턴스 변수 name가 정의되어 있지 않기 때문에 사용할 수 없다.
2-2) 인자로 주어진 객체(o)를 인스턴스 자신과 비교하여 작으면 음수, 같으면 0, 크면 양수를 반환하도록 구현해야 한다.
문자열의 경우 문자열 비교를 위해 구현된 String클래스의 compareTo()를 호출하면 된다.
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {Comparable, Comparator
객체를 정렬하는데 필요한 메서드를 정의한 인터페이스(정렬 기준 제공)
* 두 객체를 비교할 목적으로 사용(자기 자신과 비교 vs 자기 자신과 비교하지 않음)
* 두 객체의 비교 결과를 반환하도록 구현해야 함(음수(비교값 보다 작음), 0(같음), 양수(비교값 보다 큼))
* Arrays.sort(arr); : 기본 정렬 기준(Comparable)으로 정렬(오름차순)
* Arrays.sort(arr, new DescComp()); : DescComp(Comparator)에 구현된 정렬 기준으로 정렬(내림차순)
Comparable
java.lang.Comparable.compareTo() : 기본 정렬 기준(default)
* 객체를 기본(default) 정렬 방법으로 정렬할 때 사용(오름차순)
* compareTo() : 자기 자신을 기준으로 상대방과의 차이 값을 비교한다.
* 정렬 기준을 정하지 않고 Collections.sort()를 호출하면 클래스내 구현된 compareTo()에 의해 정렬된다.
// o1.compareTo(o2) : this(o1)와 o2를 비교 public interface Comparable { public int compareTo(Object o); }
Comparator
java.util.Comparator.compare() : 다른 기준으로 정렬
* 객체를 기본 정렬(오름차순) 외의 다른 기준으로 정렬할 때 사용(ex. 내림차순)
* compare() : 객체 자체와는 상관 없이 인자로 받은 두 객체를 비교한다.
ex) a.compare(b, c) : a객체와는 상관없이 b와 c객체를 비교(어떤 객체를 통해 호출하던 상관 없음(일관성 X))
* 비교 기능을 클래스와 분리하려면 익명 클래스를 활용하면 된다.
// compare(o1, o2) : 두 대상(o1, o2)을 비교 public interface Comparator { int compare(Object o1, Object o2); boolean equals(Object obj); }
Collections.sort(List list)를 이용하면 ArrayList에 저장된 요소들을 쉽게 정렬할 수 있다.
1) 단, ArrayList에 저장된 요소들이 모두 Comparable인터페이스를 구현한 것이어야 한다.
2) 정렬 기준(Comparator)를 지정하지 않으면 객체에 구현된 Comparable에 따라 정렬된다.
* sort(List list) : [대상] 객체가 구현한 Comparable에 의한 정렬
: Collections.sort()에 의해 Comparable.compareTo()가 호출된다.
* sort(List list, Comparator c) : [대상, 기준] 지정한 Comparator에 의한 정렬(적절)
static void sort(Object[] a)
static void sort(Object[] a, Comparator c)class Exercise11_5 {
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add(new Student("홍길동", 1, 1, 100, 100, 100)); // class Student implements Comparable
list.add(new Student("남궁성", 1, 2, 90, 70, 80));
list.add(new Student("김자바", 1, 3, 80, 80, 90));
list.add(new Student("이자바", 1, 4, 70, 90, 70));
list.add(new Student("안자바", 1, 5, 60, 100, 80));
Collections.sort(list); // list에 저장된 요소들을 정렬(Comparable.compareTo() 호출)
Iterator it = list.iterator();
while(it.hasNext())
System.out.println(it.next());
}
}
지네릭스(generics)를 적용한 답
class Student implements Comparable<Student> {
// 생략
public int compareTo(Student s) {
return name.compareTo(s.name);
}
}
class Exercise11_5_2 {
public static void main(String[] args) {
ArrayList<Student> list = new ArrayList<Student>();
list.add(new Student("홍길동", 1, 1, 100, 100, 100));
list.add(new Student("남궁성", 1, 2, 90, 70, 80));
list.add(new Student("김자바", 1, 3, 80, 80, 90));
list.add(new Student("이자바", 1, 4, 70, 90, 70));
list.add(new Student("안자바", 1, 5, 60, 100, 80));
Collections.sort(list);
Iterator it = list.iterator();
while(it.hasNext())
System.out.println(it.next());
}
}
[11-6] 다음의 코드는 성적 평균의 범위별로 학생 수를 세기 위한 것이다.
TreeSet이 학생들의 평균을 기준으로 정렬하도록 compare(Object o1, Object o2)와 평균 점수의 범위를 주면
해당 범위에 속한 학생의 수를 반환하는 getGroupCount()를 완성하라.
[Hint] TreeSet의 subSet(Object from, Object to)를 사용하라.
import java.util.*;
class Student implements Comparable {
String name;
int ban, no;
int kor, eng, math;
Student(String name, int ban, int no, int kor, int eng, int math) {
this.name = name;
this.ban = ban;
this.no = no;
this.kor = kor;
this.eng = eng;
this.math = math;
}
int getTotal() {
return kor + eng + math;
}
float getAverage() {
return (int)((getTotal() / 3f) * 10 + 0.5) / 10f;
}
public String toString() {
return name + ", " + ban + ", " + no + ", " + kor + ", " + eng + ", " + math
+ ", " + getTotal() + ", " + getAverage();
}
public int compareTo(Object o) {
if(o instanceof Student) {
Student tmp = (Student)o;
return name.compareTo(tmp.name);
} else {
return -1;
}
}
}
class Exercise11_6 {
static int getGroupCount(TreeSet tset, int from, int to) {
// (1) 알맞은 코드를 넣어 완성하시오.
}
public static void main(String[] args) {
TreeSet set = new TreeSet(new Comparator() {
public int compare(Object o1, Object o2) {
// (2) 알맞은 코드를 넣어 완성하시오.
}
});
set.add(new Student("홍길동", 1, 1, 100, 100, 100));
set.add(new Student("남궁성", 1, 2, 90, 70, 80));
set.add(new Student("김자바", 1, 3, 80, 80, 90));
set.add(new Student("이자바", 1, 4, 70, 90, 70));
set.add(new Student("안자바", 1, 5, 60, 100, 80));
Iterator it = set.iterator();
while(it.hasNext())
System.out.println(it.next());
System.out.println("[60 ~ 69] : " + getGroupCount(set, 60, 70));
System.out.println("[70 ~ 79] : " + getGroupCount(set, 70, 80));
System.out.println("[80 ~ 89] : " + getGroupCount(set, 80, 90));
System.out.println("[90 ~ 100] : " + getGroupCount(set, 90, 101));
}
}
// 이자바, 1, 4, 70, 90, 70, 230, 76.7
// 남궁성, 1, 2, 90, 70, 80, 240, 80.0
// 안자바, 1, 5, 60, 100, 80, 240, 80.0
// 김자바, 1, 3, 80, 80, 90, 250, 83.3
// 홍길동, 1, 1, 100, 100, 100, 300, 100.0
// [60 ~ 69] : 0
// [70 ~ 79] : 1
// [80 ~ 89] : 3
// [90 ~ 100] : 1
나의 답 :
static int getGroupCount(TreeSet tset, int from, int to) {
Integer[] average = new Integer[5]; // tset의 평균 값을 저장할 배열
Iterator<Student> it = tset.iterator(); // tset에 저장된 요소들을 읽기 위해 Iterator 생성
while (it.hasNext()) { // hasNext() : 읽어 올 요소가 있는지 확인
for (int i = 0; i < average.length; i++) {
average[i] = (int) it.next().getAverage(); // 읽어온 평균 값을 배열 average에 저장
}
}
TreeSet av_set = new TreeSet(
new Comparator() { // TreeSet에 객체를 저장하려면 비교 기준을 정의해야 함
public int compare(Object o1, Object o2) {
// Integer객체를 비교해야하니까 o1, o2를 Integer로 형변환
return (Integer)o1 > (Integer)o2 ? 1 : -1;
}
}
);
for (Integer tmp : average) { // 배열에 저장한 값을 TreeSet에 저장
av_set.add(tmp);
}
return av_set.subSet(from, to).size(); // 범위 탐색 : 범위(from ~ to)에 해당하는 데이터의 개수 반환
}
public static void main(String[] args) {
TreeSet set = new TreeSet(new Comparator() { // 익명 클래스
public int compare(Object o1, Object o2) {
if (o1 instanceof Student && o2 instanceof Student) {
Student s1 = (Student) o1;
Student s2 = (Student) o2;
return (s1.getAverage() > s2.getAverage()) ? 1 : -1; // 중복 값 처리
}
return -1;
}
});
// 생략
}1) getGroupCount() : tset의 평균값을 배열 average에 담은 뒤 TreeSet에 저장하여 범위 탐색(subSet())을 수행한다.
1-1) 평균값을 저장할 Integer배열 average를 생성한다.
* tset는 Student객체가 들어있는 데이터 집합이므로 tset와 비교 가능한 대상은 Student객체이다.
* 범위 값(from, to)을 점수로 갖는 Student객체를 임의로 생성하여 subSet()에 대입해야 한다.
* 평균값을 Integer배열에 저장하면 정수(from, to)로 범위 탐색을 수행할 수 있다.
1-2) tset에 저장된 요소들을 읽기 위해 Iterator를 생성한다.
* Set은 데이터의 중복을 허용하지 않고, 저장 순서를 유지(보장)하지 않는 데이터의 집합이다.
* Iterator(반복자)를 통해 저장된 객체(데이터)를 읽어와야 한다(특정 객체에 직접 접근 불가)
* Iterator는 컬렉션에 저장된 요소(데이터)에 접근하는데 사용되는 인터페이스이다.
* 컬렉션에 저장된 요소들을 읽어오는 방법을 표준화하여 일관성, 재사용성의 이점을 얻는다.
* 단, Collection에 정의된 메서드이므로 Collection의 자손(List, Set)이 아닌 Map에는 사용할 수 없다.
1-3) hasNext()를 통해 읽어올 요소가 있는지 확인한 후 next()를 이용하여 데이터를 읽어와야 한다.
* next()는 더 이상 읽어올 데이터가 없으면 NoSuchElementException가 발생한다.
* next()를 호출하기 전 먼저 hasNext()를 통해 읽어올 요소가 있는지 확인해야 안전하다.
* hasNext() : 읽어올 다음 요소가 있는지 확인한다.
* Object next() : cursor가 가리키는 요소를 읽어온 후 다음 요소를 가리킨다(정의하기 복잡)
1-4) next()를 통해 읽어온 tset에 저장된 객체(데이터) 중 평균값만 배열 average에 저장한다.
* Iterator의 지네릭스 타입을 Student로 정의해야 평균값을 가져올 수 있다.
1-5) average에 저장한 값을 저장하기 위한 새로운 TreeSet를 생성한다.
* TreeSet에 객체를 저장 or 비교하려면 비교 기준을 정의해야 한다.
* Integer객체를 저장할거니까 o1, o2를 Integer타입으로 형변환해야 한다.
* Object(참조형)타입은 부등호로 비교 불가하므로 형변환을 하지 않으면 컴파일 에러가 발생한다.
* TreeSet은 중복을 허용하지 않으므로 두 학생의 평균값이 같다면 한 학생의 평균은 저장되지 않는다.
* compare()는 크다/같다/작다를 결과로 반환. 0(같음)을 -1(작다)로 반환하면 중복 객체가 아닌걸로 간주된다.
* 정확한 결과를 얻으려면 비교 기준을 하나 더 만들어야 하는데 비교할 기준이 평균 값 밖에 없다.
2) main() : Student객체가 들어있는 데이터 집합인 set의 비교 기준을 정의한다.
* 여기에도 평균값이 같은 학생의 데이터를 처리하기 위해 0(같음)을 -1(작다)로 반환한다.
해설 :
static int getGroupCount(TreeSet tset, int from, int to) {
// new Student(name, ban, no, kor, eng, math)
Student s1 = new Student("", 0, 0, from, from, from);
Student s2 = new Student("", 0, 0, to, to, to);
return tset.subSet(s1, s2).size();
}
public static void main(String[] args) {
TreeSet set = new TreeSet(new Comparator() { // 익명 클래스
public int compare(Object o1, Object o2) {
if (o1 instanceof Student && o2 instanceof Student) {
Student s1 = (Student) o1;
Student s2 = (Student) o2;
return (int)(s1.getAverage() - s2.getAverage());
}
return -1;
}
});
// 생략
}평균이 지정된 범위(from~to)에 속하는 학생의 수를 세는 getGroupCount()를 작성하는 문제이다.
TreeSet은 정렬된 상태로 요소(element)를 저장하며 검색과 정렬(특히 부분정렬)에 유리하다.
1) getGroupCount()
* TreeSet클래스의 subSet()는 지정된 범위에 속하는 요소들이 포함된 TreeSet을 반환한다.
* 단, 끝 범위의 경계값(to)은 결과에 포함되지 않는다.(from ≤ x < to)
* to를 포함하려면 subSet(E fromElement, boolean fromInclusive, E toElement, boolean tolnclusive)를 사용해야 한다.
2) main()
* compare(Object o1, Object o2)는 주어진 두 객체를 비교해서 그 결과를 양수, 0, 음수 중의 하나로 반환한다.
* 학생 점수의 평균을 반환하는 getAverage()로 계산한 다음에 int타입으로 형변환해주었다.
TreeSet의 정렬 기준
TreeSet은 요소(element)를 저장할 때 정렬해서 저장하는데, 그 정렬 기준은 어떤 것일까?
* Comparable를 구현한 클래스의 객체들은 TreeSet에 저장할 때, 정렬 기준을 지정해주지 않아도 된다.
* Comparable를 구현하지 않은 클래스는 생성자 TreeSet(Comparator c)를 이용하여 정렬 기준을 제공해야 한다.
* Comparable를 구현한 클래스 : Integer와 같은 wrapper클래스, String는 정렬 기준이 내부에 정의되어 있다.
* 내부에 정렬 기준이 정의되어 있어도 다른 기준으로 정렬하고 싶을 때 TreeSet(Comparator c)를 사용하면 된다.
class Student implements Comparable { // Comparable : 기본 정렬 기준 String name; // 생략 public int compareTo(Object o) { if(o instanceof Student) { Student tmp = (Student)o; return name.compareTo(tmp.name); // 이름을 기준으로 정렬(오름차순) // return tmp.name.compareTo(name); // 이름을 기준으로 정렬(내림차순) } else { return -1; } } }
평균을 기준으로 오름차순 정렬을 하기 위해서는 다른 정렬 기준을 제공해야 한다.
* Comparator를 구현한 클래스를 작성한다.
* 이 클래스의 인스턴스를 생성자 TreeSet(Comparator c)의 매개변수로 넘겨준다.
* 매개변수로 넘겨진 정렬 기준은 TreeSet의 멤버 변수로 정의된 comparator에 저장된다.
* comparator는 TreeSet에 요소를 저장할 때 사용되는 put()에서 저장할 위치를 결정하기 위해 사용된다.// TreeSet(Comparator c) TreeSet set = new TreeSet(new Comparator() { // 익명 클래스 public int compare(Object o1, Object o2) { // 생략 } }// TreeSet의 원본 소스를 이해하기 쉽게 재구성한 것(원본과 다름) TreeSet set = new TreeSet(new Comparator(){...}); // Comparator를 제공받는다. class TreeSet { private Comparator comparator = null; // Comparator(정렬 기준) TreeSet(Comparator c) { this.comparator = c; // 생성자를 통해 제공받은 정렬 기준을 comparator로 설정 } // TreeSet에 요소를 저장하는데 사용되는 메서드. // 저장할 때 정렬해서 저장하므로 compare()를 호출 public Object put(Object key, Object value) { // 생략 while(true) { int cmp = comparator.compare(key, t.key); // compare() 호출 // 생략 } // 생략 } }
/**
* 객체로 범위값을 어떻게 구했을까?
* - Student 객체가 들어있는 데이터 집합에 어떤 비교대상은 Student일 수 밖에 없다.
* - 그래서 Student객체를 임의로 생성하여 비교 가능
* - 평균으로 비교하도록 Comparator(비교 기준)를 작성했기 때문에 가능
*/
[11-7] 다음에 제시된 BanNoAscending클래스를 완성하여,
ArrayList에 담긴 Student인스턴스들이 반(ban)과 번호(no)로 오름차순 정렬되게 하시오.
(반이 같은 경우 번호를 비교해서 정렬한다.)
import java.util.*;
class Student {
String name;
int ban, no;
int kor, eng, math;
Student(String name, int ban, int no, int kor, int eng, int math) {
this.name = name;
this.ban = ban;
this.no = no;
this.kor = kor;
this.eng = eng;
this.math = math;
}
int getTotal() {
return kor + eng + math;
}
float getAverage() {
return (int)((getTotal() / 3f) * 10 + 0.5) / 10f;
}
public String toString() {
return name + ", " + ban + ", " + no + ", " + kor + ", " + eng + ", " + math + ", " + getTotal() + ", " + getAverage();
}
}
class BanNoAscending implements Comparator {
public int compare(Object o1, Object o2) {
// (1) 알맞은 코드를 넣어 완성하시오.
}
}
class Exercise11_7 {
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add(new Student("이자바", 2, 1, 70, 90, 70));
list.add(new Student("안자바", 2, 2, 60, 100, 80));
list.add(new Student("홍길동", 1, 3, 100, 100, 100));
list.add(new Student("남궁성", 1, 1, 90, 70, 80));
list.add(new Student("김자바", 1, 2, 80, 80, 90));
Collections.sort(list, new BanNoAscending());
Iterator it = list.iterator();
while(it.hasNext())
System.out.println(it.next());
}
}
// 남궁성, 1, 1, 90, 70, 80, 240, 80.0
// 김자바, 1, 2, 80, 80, 90, 250, 83.3
// 홍길동, 1, 3, 100, 100, 100, 300, 100.0
// 이자바, 2, 1, 70, 90, 70, 230, 76.7
// 안자바, 2, 2, 60, 100, 80, 240, 80.0
나의 답 : 삼항 연산자를 이용하여 s1과 s2가 같은 반인 경우 번호로 비교한 값을 반환하도록 한다.
class BanNoAscending implements Comparator {
public int compare(Object o1, Object o2) {
if (o1 instanceof Student2 && o2 instanceof Student2) {
Student2 s1 = (Student2) o1;
Student2 s2 = (Student2) o2;
return (s1.ban == s2.ban) ? (s1.no - s2.no) : (s1.ban - s2.ban);
}
return -1;
}
}
해설 : 반(ban)을 뺄셈한 결과가 0이면(반이 같으면), 번호(no)를 뺄셈해서 반환하면 된다.
class BanNoAscendings implements Comparator { // 해설 답안
public int compare(Object o1, Object o2) {
// (1) 알맞은 코드를 넣어 완성하시오.
if (o1 instanceof Student2 && o2 instanceof Student2) {
Student2 s1 = (Student2) o1;
Student2 s2 = (Student2) o2;
int result = s1.ban - s2.ban;
if (result == 0) { // 반이 같으면, 번호를 비교한다.
return s1.no - s2.no;
}
return result;
}
return -1;
}
}
[11-8] 문제 11-7의 Student클래스에 총점(total)과 전교등수(schoolRank)를 저장하기 위한 인스턴스 변수를 추가하였다.
Student클래스의 기본 정렬을 이름(name)이 아닌 총점(total)을 기준으로 한 내림차순으로 변경한 다음,
총점을 기준으로 각 학생의 전교등수를 계산하고 전교등수를 기준으로 오름차순 정렬하여 출력하시오.
import java.util.*;
class Student implements Comparable {
String name;
int ban;
int no;
int kor;
int eng;
int math;
int total; // 총점
int schoolRank; // 전교 등수
Student(String name, int ban, int no, int kor, int eng, int math) {
this.name = name;
this.ban = ban;
this.no = no;
this.kor = kor;
this.eng = eng;
this.math = math;
total = kor + eng + math;
}
int getTotal() {
return total;
}
float getAverage() {
return (int)((getTotal() / 3f) * 10 + 0.5) / 10f;
}
// 총점(total)을 기준으로 한 내림차순
public int compareTo(Object o) {
// (1) 알맞은 코드를 넣어 완성하시오.
}
public String toString() {
return name + ", " + ban + ", " + no + ", " + kor + ", " + eng + ", " + math
+ ", " + getTotal() + ", " + getAverage() + ", " + schoolRank;
}
}
class Exercise11_8 {
public static void calculateSchoolRank(List list) {
Collections.sort(list); // list를 총점 기준 내림차순으로 정렬
int prevRank = -1; // 이전 전교등수
int prevTotal = -1; // 이전 총점
int length = list.size();
/*
(2) 아래의 로직에 맞게 코드를 작성하시오.
1. 반복문을 이용하여 list에 저장된 Student객체를 하나씩 읽는다.
2. 총점(total)이 이전 총점(prevTotal)과 같으면 이전 등수(prevRank)를 등수(schoolRank)로 한다.
3. 총점이 서로 다르면, 등수(schoolRank)의 값을 알맞게 계산하여 저장한다.
이전에 동점자 였다면, 그 다음 등수는 동점자의 수를 고려해야 한다.(실행결과 참고)
4. 현재 총점과 등수를 이전 총점(prevTotal)과 이전 등수(prevRank)에 저장한다.
*/
}
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add(new Student("이자바", 2, 1, 70, 90, 70));
list.add(new Student("안자바", 2, 2, 60, 100, 80));
list.add(new Student("홍길동", 1, 3, 100, 100, 100));
list.add(new Student("남궁성", 1, 1, 90, 70, 80));
list.add(new Student("김자바", 1, 2, 80, 80, 90));
calculateSchoolRank(list);
Iterator it = list.iterator();
while(it.hasNext())
System.out.println(it.next());
}
}
// 홍길동, 1, 3, 100, 100, 100, 300, 100.0, 1
// 김자바, 1, 2, 80, 80, 90, 250, 83.3, 2
// 안자바, 2, 2, 60, 100, 80, 240, 80.0, 3
// 남궁성, 1, 1, 90, 70, 80, 240, 80.0, 3
// 이자바, 2, 1, 70, 90, 70, 230, 76.7, 5
나의 답 :
// 총점(total)을 기준으로 한 내림차순
public int compareTo(Object o) {
if (o instanceof Student) {
Student tmp = (Student) o;
return tmp.total - this.total;
} else {
return -1;
}
}
class Exercise11_8 {
public static void calculateSchoolRank(List list) {
Collections.sort(list); // list를 총점 기준 내림차순으로 정렬
int prevRank = -1; // 이전 전교등수
int prevTotal = -1; // 이전 총점
int length = list.size();
// 1. 반복문을 이용하여 list에 저장된 Student객체를 하나씩 읽는다.
for (int i = 0; i < length; i++) {
Student s = (Student)list.get(i);
// 2. 총점(total)이 이전 총점(prevTotal)과 같으면 이전 등수(prevRank)를 등수(schoolRank)로 한다.
if (s.total == prevTotal) {
s.schoolRank = prevRank; // 동점자는 등수(i)를 증가시키지 않고 이전 등수를 저장한다.
} else {
// 3. 총점이 서로 다르면, 등수(schoolRank)의 값을 알맞게 계산하여 저장한다.
// 이전에 동점자 였다면, 그 다음 등수는 동점자의 수를 고려해야 한다.(실행결과 참고)
s.schoolRank = i + 1; // 동점자가 아니면 등수(i)를 증가시킴(1 -> 2 -> 3 -> 5)
}
// 4. 현재 총점과 등수를 이전 총점(prevTotal)과 이전 등수(prevRank)에 저장한다.
prevTotal = s.total;
prevRank = s.schoolRank;
// [300, 1] -> [250, 2] -> [240, 3] -> [240, 3] -> [230, 5]
}
}
// 생략
}1) compareTo()
1-1) 내림차순으로 정렬하려면 기본 정렬 방식의 역(반대)을 반환하거나 비교하는 객체의 위치를 변경하면 된다.
* 오름차순 : 반환 결과가 양수(2 < 1)이면 자리 바꿈 O, 0 or 음수(1 < 2)이면 자리 바꿈 X
: 양수 → 상대보다 큼(뒤에 위치), 음수 → 상대보다 작음(앞에 위치)
: 1, 2, 3, 4, 5
* 내림차순 : 반환 결과가 양수(2 < 1)이면 자리 바꿈 X, 0 or 음수(1 < 2)이면 자리 바꿈 O
: 양수 → 상대보다 작음(뒤에 위치), 음수 → 상대보다 큼(앞에 위치)
: 5, 4, 3, 2, 1
* 기본 정렬 방식의 역 : 원래 결과와 반대인 결과를 얻게 된다(-1 * -1 = 1, 1 * -1 = -1)
* 비교 객체의 위치 변경 : this.total - tmp.total → tmp.total - this.total
2) calculateSchoolRank()
2-1) ArrayList는 배열 기반 컬렉션 클래스이므로 특정 위치에 어떠한 값을 저장하거나 가져오는 게 가능하다.
* void add(int index, Object element) : 지정된 위치(index)에 객체 저장(이후의 요소들은 뒤로 밀려난다)
* get(int index) : 지정된 위치(index)에 저장된 객체 반환
* list에 저장된 학생 정보를 차례대로 하나씩 가져와 이전 학생의 총점과 비교한다.
2-2) A 학생의 총점과 B 학생의 총점이 같다면 동점자이므로 B 학생의 등수를 A 학생의 등수 값(prevRank)으로 저장한다.
(= 현재 학생의 총점(s.total)과 이전 학생의 총점(prevTotal)이 같으면 등수를 이전 등수(prevRank)로 저장)
2-3) 동점자라면 s.schoolRank에 이전 등수(prevRank)를 저장하고, 아니라면 증가시킨 등수(i + 1)를 저장한다.
2-4) 현재 총점과 등수를 저장하여 다음 학생의 총점과 비교한다(동점자라면 등수에 같은 값을 저장한다)

[11-9] 문제 11-8의 Student클래스에 반등수(classRank)를 저장하기 위한 인스턴스변수를 추가하였다.
반등수를 계산하고 반과 반등수로 오름차순 정렬하여 결과를 출력하시오.
(1)~(2)에 알맞은 코드를 넣어 완성하시오.
import java.util.*;
class Student implements Comparable {
String name;
int ban, no;
int kor, eng, math;
int total;
int schoolRank; // 전교등수
int classRank; // 반등수
Student(String name, int ban, int no, int kor, int eng, int math) {
this.name = name;
this.ban = ban;
this.no = no;
this.kor = kor;
this.eng = eng;
this.math = math;
total = kor + eng + math;
}
int getTotal() {
return total;
}
float getAverage() {
return (int)((getTotal() / 3f) * 10 + 0.5) / 10f;
}
public int compareTo(Object o) {
if(o instanceof Student) {
Student tmp = (Student)o;
return tmp.total - this.total;
} else {
return -1;
}
}
public String toString() {
return name + ", " + ban + ", " + no + ", " + kor + ", " + eng + ", " + math
+ ", " + getTotal() + ", " + getAverage() + ", " + schoolRank + ", " + classRank;
}
}
class ClassTotalComparator implements Comparator {
public int compare(Object o1, Object o2) {
// (1) 알맞은 코드를 넣어 완성하시오.
}
}
class Exercise11_9 {
public static void calculateClassRank(List list) {
Collections.sort(list, new ClassTotalComparator()); // 반별 총점 기준 내림차순으로 정렬
int prevBan = -1;
int prevRank = -1;
int prevTotal = -1;
int length = list.size();
/*
(2) 아래의 로직에 맞게 코드를 작성하시오.
1. 반복문을 이용하여 list에 저장된 Student객체를 하나씩 읽는다.
2. 반이 달라지면(ban != prevBan) 이전 등수(prevRank)와 이전 총점(prevTotal)을 초기화 한다.
3. 총점(total)이 이전 총점(prevTotal)과 같으면 이전 등수(prevRank)를 등수(classRank)로 한다.
4. 총점이 서로 다르면, 등수(classRank)의 값을 알맞게 계산하여 저장한다.
이전에 동점자였다면, 그 다음 등수는 동점자의 수를 고려해야 한다.(실행결과 참고)
5. 현재 반, 총점, 등수를 이전 반(prevBan), 이전 총점(prevTotal), 이전 등수(prevRank)에 저장한다.
*/
}
public static void calculateSchoolRank(List list) {
Collections.sort(list); // 총점 기준 내림차순으로 정렬
int prevRank = -1; // 이전 전교등수
int prevTotal = -1; // 이전 총점
int length = list.size();
for (int i = 0; i < length; i++) {
Student s = (Student)list.get(i);
if (s.total == prevTotal) {
s.schoolRank = prevRank; // 동점자는 등수(i)를 증가시키지 않고 이전 등수를 저장한다.
} else {
s.schoolRank = i + 1; // 동점자가 아니면 등수(i)를 증가시킴(1 -> 2 -> 3 -> 5)
}
prevTotal = s.total;
prevRank = s.schoolRank;
// [300, 1] -> [250, 2] -> [240, 3] -> [240, 3] -> [230, 5]
}
}
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add(new Student("이자바", 2, 1, 70, 90, 70));
list.add(new Student("안자바", 2, 2, 60, 100, 80));
list.add(new Student("홍길동", 1, 3, 100, 100, 100));
list.add(new Student("남궁성", 1, 1, 90, 70, 80));
list.add(new Student("김자바", 1, 2, 80, 80, 90));
calculateSchoolRank(list);
calculateClassRank(list);
Iterator it = list.iterator();
while(it.hasNext())
System.out.println(it.next());
}
}
// 홍길동, 1, 3, 100, 100, 100, 300, 100.0, 1, 1
// 김자바, 1, 2, 80, 80, 90, 250, 83.3, 2, 2
// 남궁성, 1, 1, 90, 70, 80, 240, 80.0, 3, 3
// 안자바, 2, 2, 60, 100, 80, 240, 80.0, 3, 1
// 이자바, 2, 1, 70, 90, 70, 230, 76.7, 5, 2
나의 답 :
class ClassTotalComparator implements Comparator {
public int compare(Object o1, Object o2) {
if (o1 instanceof Student && o1 instanceof Student) {
Student s1 = (Student) o1;
Student s2 = (Student) o2;
// return (s1.ban == s2.ban) ? s1.classRank - s2.classRank : s1.ban - s2.ban; // 오답
return (s1.ban == s2.ban) ? s2.total - s1.total : s1.ban - s2.ban;
}
return -1;
}
}
public static void calculateClassRank(List list) {
// 1. 반복문을 이용하여 list에 저장된 Student객체를 하나씩 읽는다.
for (int i = 0, n = 0; i < length; i++, n++) {
Student s = (Student) list.get(i);
// 2. 반이 달라지면(ban != prevBan) 이전 등수(prevRank)와 이전 총점(prevTotal)을 초기화한다.
if (s.ban != prevBan) {
prevRank = -1;
prevTotal = -1;
n = 0;
}
// 3. 총점(total)이 이전 총점(prevTotal)과 같으면 이전 등수(prevRank)를 등수(classRank)로 한다.
if (s.total == prevTotal) {
s.classRank = prevRank;
} else {
// 4. 총점이 서로 다르면, 등수(classRank)의 값을 알맞게 계산하여 저장한다.
// 이전에 동점자였다면, 그 다음 등수는 동점자의 수를 고려해야 한다.(실행 결과 참고)
s.classRank = n + 1;
}
// 5. 현재 반, 총점, 등수를 이전 반(prevBan), 이전 총점(prevTotal), 이전 등수(prevRank)에 저장한다.
prevBan = s.ban;
prevTotal = s.total;
prevRank = s.classRank;
}
}class Exercise11_9 {
public static void calculateClassRank(List list) {
Collections.sort(list, new ClassTotalComparator()); // 반별 총점 기준 내림차순으로 정렬
// 생략
}
// 생략
}1) ClassTotalComparator : 같은 반이라면 등수를 기준으로 정렬하고, 아니라면 반을 기준으로 정렬한다(오름차순)
* 등수 : 1등 → 2등 → 3등(오름차순)
* 반 : 1반 → 2반 → 3반(오름차순)
* 총점 : 100점 → 83점 → 80점(내림차순)
* 등수가 계산된 상태가 아니므로 같은 반이라면 총점을 비교하여 정렬(내림차순)하는 게 적절하다.
2) calculateClassRank() : 반별 등수를 계산한다.
2-1) 반복문을 이용하여 정렬 기준(ClassTotalComparator)으로 정렬된 데이터를 한 줄 씩 읽는다.
2-2) 반이 달라지면 다시 1등부터 등수를 매겨야하므로 이전 등수, 이전 총점, 등수(n)를 초기화해야 한다.
2-3) A 학생의 총점과 B 학생의 총점이 같다면 동점자이므로 B 학생의 등수를 A 학생의 등수 값(prevRank)으로 저장한다.
2-4) 등수를 매길 때 반복문의 카운터 i 대신 n을 사용해야 한다.
i를 사용하면 초기화되는 부분으로 인해 반복문이 종료되지 않는 문제가 발생한다.
2-5) 현재 반, 총점, 등수를 저장하여 다음 학생의 반, 총점과 비교한다.

[11-10] 다음 예제의 빙고판은 1~30사이의 숫자들로 만든 것인데, 숫자들의 위치가 잘 섞이지 않는다는 문제가 있다.
이러한 문제가 발생하는 이유와 이 문제를 개선하기 위한 방법을 설명하고, 이를 개선한 새로운 코드를 작성하시오.
import java.util.*;
class Exercise11_10 {
public static void main(String[] args) {
Set set = new HashSet();
int[][] board = new int[5][5];
for(int i = 0; set.size() < 25; i++) {
set.add((int)(Math.random() * 30) + 1 + "");
}
Iterator it = set.iterator();
for(int i = 0; i < board.length; i++) {
for(int j = 0; j < board[i].length; j++) {
board[i][j] = Integer.parseInt((String)it.next());
System.out.print((board[i][j] < 10 ? " " : " ") + board[i][j]);
}
System.out.println();
}
}
}
나의 답 :
import java.util.*;
class Exercise11_10 {
public static void main(String[] args) {
Set set = new LinkedHashSet(); // HashSet -> LinkedHashSet
int[][] board = new int[5][5];
for(int i = 0; set.size() < 25; i++) {
set.add((int)(Math.random() * 30) + 1 + ""); // String
}
Iterator it = set.iterator();
for(int i = 0; i < board.length; i++) {
for(int j = 0; j < board[i].length; j++) {
board[i][j] = Integer.parseInt((String)it.next());
System.out.print((board[i][j] < 10 ? " " : " ") + board[i][j]);
}
System.out.println();
}
}
}문제점) HashSet은 중복을 허용하지 않고, 데이터가 저장되는 순서를 유지(보장)하지 않는다.
그렇기 때문에 데이터를 자체적인 저장 방식(hashing 기법)에 따라 저장한다.
이로 인해 HashSet에 저장된 객체(데이터)를 여러 번 출력해보면 같은 숫자가 비슷한 위치에 출력된다.
해결 방법) LinkedHashSet를 사용하면 된다.
LinkedHashSet는 데이터가 저장되는 순서를 유지(보장)한다.
오름차순으로 정렬되는 게 아니라 데이터가 입력된 순서대로 데이터를 관리한다.
LinkedHashSet에 저장된 객체(데이터)를 출력해보면 데이터를 저장한 순서대로 출력된다.
LinkedHashSet을 사용하면 해결되는 명확한 이유가 뭔지 궁금하다(구글링 했지만 아직 답을 찾지 못함)
해설 :
import java.util.*;
class Exercise11_10 {
public static void main(String[] args) {
Set set = new HashSet();
int[][] board = new int[5][5];
for(int i = 0; set.size() < 25; i++) {
set.add((int)(Math.random() * 30) + 1 + "");
}
ArrayList list = new ArrayList(set); // set과 같은 데이터를 가진 ArrayList를 생성
Collections.shuffle(list); // list에 저장된 데이터의 순서를 섞는다.
Iterator it = list.iterator();
for(int i = 0; i < board.length; i++) {
for(int j = 0; j < board[i].length; j++) {
board[i][j] = Integer.parseInt((String)it.next());
System.out.print((board[i][j] < 10 ? " " : " ") + board[i][j]);
}
System.out.println();
}
}
}문제점) HashSet은 중복을 허용하지 않고 순서를 유지하지 않기 때문에 발생하는 문제이다.
임의의 순서로 저장하더라도, 해싱(hashing) 알고리즘은 특성상 한 숫자가 고정된 위치에 저장된다.
해싱(hashing) 알고리즘의 특성(같은 값은 같은 자리에 저장된다) 때문에 잘 섞이지 않는 문제가 발생한 것.
해결 방법) 저장 순서를 유지하는 List인터페이스를 구현한 컬렉션 클래스를 사용하도록 변경해야 한다.
1) 저장 순서를 유지하는 ArrayList에 HashSet의 데이터를 옮겨 담는다.
* 대부분의 컬렉션 클래스들은 다른 컬렉션으로 데이터를 쉽게 옮길 수 있게 설계되어 있다.
* 매개 변수의 타입이 Collection인터페이스이므로
Collection인터페이스의 자손(List, Set)을 구현한 모든 클래스의 인스턴스를 인자로 받을 수 있다.
2) Collections.shuffle()을 이용해서 저장된 데이터들의 순서를 뒤섞는다.
ArrayList(Collection<? extends E> c)
LinkedList(Collection<? extends E> c)
Vector(Collection<? extends E> c)
HashSet(Collection<? extends E> c)
TreeSet(Collection<? extends E> c)
LinkedHashSet(Collection<? extends E> c)
[11-11] 다음은 SutdaCard클래스를 HashSet에 저장하고 출력하는 예제이다.
HashSet에 중복된 카드가 저장되지 않도록 SutdaCard의 hashCode()를 알맞게 오버라이딩하시오.
[Hint] String클래스의 hashCode()를 사용하라.
import java.util.*;
class SutdaCard {
int num;
boolean isKwang;
SutdaCard() {
this(1, true);
}
SutdaCard(int num, boolean isKwang) {
this.num = num;
this.isKwang = isKwang;
}
public boolean equals(Object obj) {
if(obj instanceof SutdaCard) {
SutdaCard c = (SutdaCard)obj;
return num == c.num && isKwang == c.isKwang;
} else {
return false;
}
}
public String toString() {
return num + (isKwang ? "K" : "");
}
}
class Exercise11_11 {
public static void main(String[] args) {
SutdaCard c1 = new SutdaCard(3, true);
SutdaCard c2 = new SutdaCard(3, true);
SutdaCard c3 = new SutdaCard(1, true);
HashSet set = new HashSet();
set.add(c1);
set.add(c2);
set.add(c3);
System.out.println(set);
}
}
// [3K, 1K]
나의 답 :
class SutdaCard {
int num;
boolean isKwang;
SutdaCard() {
this(1, true);
}
SutdaCard(int num, boolean isKwang) {
this.num = num;
this.isKwang = isKwang;
}
public boolean equals(Object obj) {
if(obj instanceof SutdaCard) {
SutdaCard c = (SutdaCard)obj;
return num == c.num && isKwang == c.isKwang;
} else {
return false;
}
}
public int hashCode() {
return toString().hashCode(); // String.hashCode() 호출
}
public String toString() {
return num + (isKwang ? "K" : "");
}
}Q) 예제의 코드를 실행해보면 중복이 제거되지 않은 결과를 얻게 된다. [1K, 3K, 3K]
중복을 허용하지 않는 HashSet에 객체(데이터)를 담았는데 중복이 제거되지 않은 이유가 뭘까?
A) hashCode()를 오버라이딩 하지 않았기 때문이다.
오버라이딩 하지 않은 hashCode()는 iv의 값이 같은 두 객체를 서로 다른 객체로 인식한다.
hashCode()를 오버라이딩한 후에는 중복이 제거된 결과를 얻게 된다. [3K, 1K]
toString()에 hashCode()를 호출하는 방법으로 쉽게 hashCode()를 오버라이딩할 수 있다.
인스턴스 변수(num, isKwang)들의 값을 결합한 문자열을 만들고, 그 문자열에 대해 hashCode()를 호출한다.
1) String.hashCode() : 객체의 주소가 아닌 문자열의 내용을 기반으로 해시 코드를 생성한다.
* 문자열의 내용이 같으면 항상 같은 값의 해시 코드를 반환한다(iv 값이 같은 두 객체가 같은 해시 코드를 얻음)
2) SutdaCard.toString() : num과 isKwang의 값을 결합한 문자열을 만들어 반환한다.
Object.hashCode()
오버라이딩하지 않은 기본 hashCode()
클래스 이름 + 메모리 주소와 관련된 정수 값으로 이뤄져 있다.
* 두 객체가 같은 hashCode() 값을 가질 수 없다(서로 다른 두 객체가 같은 메모리 번지에 존재할 수 없음)
* 대부분의 경우 서로 다른 객체라도 클래스의 인스턴스 변수 값이 같으면, 같은 객체로 인식해야 한다.
ex) SutdaCard클래스 : num, isKwang의 값이 같으면 같은 객체이다.
* equals()와 hashCode()를 적절히 오버라이딩해야 한다.
equals()의 결과가 true이어야 하고, 두 객체의 해시코드(hashCode()를 호출한 결과)가 같아야 한다.
* HashSet에 객체(데이터)를 담을 때는 equals()와 hashCode()를 오버라이딩해야 한다(해시 알고리즘 사용)
* HashSet에 객체(데이터)를 담는 게 아니라면 equals()만 오버라이딩하면 된다.
[11-12] 다음은 섯다게임에서 카드의 순위를 결정하는 등급 목록(족보)이다.
HashMap에 등급과 점수를 저장하는 registerJokbo()와 게임 참가자의 점수를 계산해서 반환하는 getPoint()를 완성하시오.
[참고] 섯다게임은 두 장의 카드의 숫자를 더한 값을 10으로 나눈 나머지가 높은 쪽이 이기는 게임이다.
그 외에도 특정 숫자로 구성된 카드로 이루어진 등급(족보)이 있어서 높은 등급의 카드가 이긴다.
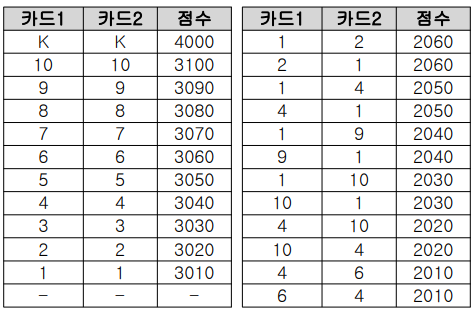
import java.util.*;
class Exercise11_12 {
public static void main(String args[]) throws Exception {
SutdaDeck deck = new SutdaDeck();
deck.shuffle();
Player p1 = new Player("타짜", deck.pick(), deck.pick());
Player p2 = new Player("고수", deck.pick(), deck.pick());
System.out.println(p1 + " " + deck.getPoint(p1));
System.out.println(p2 + " " + deck.getPoint(p2));
}
}
class SutdaDeck {
final int CARD_NUM = 20;
SutdaCard[] cards = new SutdaCard[CARD_NUM];
int pos = 0; // 다음에 가져올 카드의 위치
HashMap jokbo = new HashMap(); // 족보를 저장할 HashMap
SutdaDeck() {
for(int i = 0; i < cards.length; i++) {
int num = i % 10 + 1;
boolean isKwang = i < 10 && (num == 1 || num == 3 || num == 8);
cards[i] = new SutdaCard(num, isKwang);
}
registerJokbo(); // 족보(등급, 점수) 등록
}
void registerJokbo() {
/*
(1) 아래의 로직에 맞게 코드를 작성하시오.
1. jokbo(HashMap)에 족보를 저장한다.
2. 두 카드의 값(등급)을 문자열로 붙여서 key로, 점수를 value로 저장한다.
*/
}
int getPoint(Player p) {
if(p == null) return 0;
SutdaCard c1 = p.c1;
SutdaCard c2 = p.c2;
Integer result = 0;
/*
(2) 아래의 로직에 맞게 코드를 작성하시오.
1. 카드 두 장이 모두 광이면, jokbo에서 키를 "KK"로 하여 점수를 조회한다.
2. 두 카드의 숫자(num)로 jokbo에서 등급을 조회한다.
3. 해당하는 등급이 없으면, 아래의 공식으로 점수를 계산한다.
(c1.num + c2.num) % 10 + 1000
4. Player의 점수(point)에 계산한 값을 저장한다.
*/
return result.intValue();
}
SutdaCard pick() throws Exception {
SutdaCard c = null;
if(0 <= pos && pos < CARD_NUM) {
c = cards[pos];
cards[pos++] = null;
} else {
throw new Exception("남아있는 카드가 없습니다.");
}
return c;
}
void shuffle() {
for(int x = 0; x < CARD_NUM * 2; x++) {
int i = (int)(Math.random() * CARD_NUM);
int j = (int)(Math.random() * CARD_NUM);
SutdaCard tmp = cards[i];
cards[i] = cards[j];
cards[j] = tmp;
}
}
}
class Player {
String name;
SutdaCard c1;
SutdaCard c2;
int point; // 카드의 등급에 따른 점수
Player(String name, SutdaCard c1, SutdaCard c2) {
this.name = name;
this.c1 = c1;
this.c2 = c2;
}
public String toString() {
return "[" + name + "] : " + c1.toString() + ", " + c2.toString();
}
}
class SutdaCard {
int num;
boolean isKwang;
SutdaCard() {
this(1, true);
}
SutdaCard(int num, boolean isKwang) {
this.num = num;
this.isKwang = isKwang;
}
public String toString() {
return num + (isKwang ? "K" : "");
}
}
// [타짜] : 5, 9 1004
// [고수] : 1, 1K 3010
나의 답 :
void registerJokbo() {
// 1. jokbo(HashMap)에 족보를 저장한다.
// 2. 두 카드의 값(등급)을 문자열로 붙여서 key로, 점수를 value로 저장한다.
jokbo.put("KK", 4000);
jokbo.put("1010", 3100);
jokbo.put("99", 3090);
jokbo.put("88", 3080);
jokbo.put("77", 3070);
jokbo.put("66", 3060);
jokbo.put("55", 3050);
jokbo.put("44", 3040);
jokbo.put("33", 3030);
jokbo.put("22", 3020);
jokbo.put("11", 3010);
jokbo.put("12", 2060);
jokbo.put("21", 2060);
jokbo.put("14", 2050);
jokbo.put("41", 2050);
jokbo.put("19", 2040);
jokbo.put("91", 2040);
jokbo.put("110", 2030);
jokbo.put("101", 2030);
jokbo.put("104", 2020);
jokbo.put("410", 2020);
jokbo.put("46", 2010);
jokbo.put("64", 2010);
}
int getPoint(Player p) {
if(p == null) return 0;
SutdaCard c1 = p.c1;
SutdaCard c2 = p.c2;
Integer result = 0;
// 1. 카드 두 장이 모두 광이면, jokbo에서 키를 "KK"로 하여 점수를 조회한다.
if (c1.isKwang && c2.isKwang) {
result = (Integer) jokbo.get("KK");
} else {
// 2. 두 카드의 숫자(num)로 jokbo에서 등급을 조회한다.
result = (Integer) jokbo.get("" + c1.num + c2.num);
// 3. 해당하는 등급이 없으면, 아래의 공식으로 점수를 계산한다.
// (c1.num + c2.num) % 10 + 1000
if (result == null) {
result = new Integer(((c1.num + c2.num) % 10 + 1000));
}
}
// 4. Player의 점수(point)에 계산한 값을 저장한다.
p.point = result.intValue(); // Integer -> int(생략 가능)
return result.intValue(); // Integer -> int(생략 가능)
}1) registerJokbo()
put(Object key, Object value)를 이용하여 지정한 key(두 카드의 값)와 value(점수)를 HashMap에 저장한다.
* 원칙상으로는 매개 변수의 타입이 Object(참조형)라 인자로 Wrapper class를 넘겨줘야 한다.
* 래퍼 클래스(Wrapper class) : 8개의 기본 타입에 해당하는 데이터를 객체로 포장해 주는 클래스(출처 : TCP School)
* 기본형(primitive type)을 인자로 넘겨줬는데 컴파일 에러가 발생하지 않는 이유?
오토박싱(JDK1.5)으로 인해 컴파일러가 기본형으로 작성한 코드를 Wrapper class 코드로 자동 변환한다.
jokbo.put("KK", 4000);
jokbo.put("KK", new Integer(4000));2) getPoint(Player p) : 게임 참가자(Player)가 가진 카드로 점수를 계산한다.
get(Object key)를 통해 두 카드의 값(key)에 해당하는 점수(value)를 족보(jokbo)에서 가져온다.
* Object get(Object key) : 지정한 키(key)에 해당하는 값(객체)을 반환한다(못 찾으면 null을 반환)
* 반환 타입이 Object(참조형)이므로 결과를 Integer(Wrapper class)에 저장한다(형변환 필요)
2-1) 카드 두 장이 모두 광(isKwang)이면, 족보에서 "KK"(key)에 해당하는 점수(value)를 가져와 결과(result)에 저장한다.
2-2) 아니라면, 두 카드의 값(c1.num, c2.num)를 문자열로 만들어 족보에 해당하는 등급(key)을 조회한다.
족보의 key가 문자열이므로 두 카드의 값(c1.num, c2.num)를 문자열로 만든 다음 get()를 호출해야 한다.
2-3) get()의 반환 결과가 null이면 족보에 없는 값(등급)이라는 걸 의미한다.
족보에 없는 숫자 조합(등급)이라면, 공식(c1.num + c2.num) % 10 + 1000)으로 점수를 계산한다.
2-4) 결과를 점수(point)에 저장하고 반환한다.
* 점수(point)가 int타입이므로 Integer타입을 int타입으로 변환한다.
* getPoint()의 반환 타입이 int타입이므로 Integer타입을 int타입으로 변환한다.
* 오토박싱(JDK1.5)으로 인해 변환(Integer → int) 과정을 생략해도 컴파일 에러가 발생하지 않는다.
HashMap
Map인터페이스를 구현한 대표적인 컬렉션 클래스
* 데이터를 키(key)와 값(value)으로 묶어 하나의 쌍(Entry)으로 저장한다.
키(key) : 저장된 값(value)을 찾는데 사용되므로 고유한 값이어야 한다(중복을 허용하지 않음)
값(value) : 키(key)와 달리 데이터의 중복을 허용한다.
* 데이터를 해싱(hashing)기법으로 저장한다(데이터가 많아도 검색 빠름)
* 키가 중복되면 나중에 저장한 값으로 덮어쓰게 된다.
[11-13] 다음 코드는 문제 11-12를 발전시킨 것으로 각 Player들의 점수를 계산하고, 점수가 제일 높은 사람을 출력하는 코드이다. TreeMap의 정렬 기준을 점수가 제일 높은 사람부터 내림차순이 되도록 아래의 코드를 완성하시오.
단, 동점자 처리는 하지 않는다.
import java.util.*;
class Exercise11_13 {
public static void main(String args[]) throws Exception {
SutdaDeck deck = new SutdaDeck();
deck.shuffle();
Player[] pArr = {
new Player("타짜", deck.pick(), deck.pick()),
new Player("고수", deck.pick(), deck.pick()),
new Player("물주", deck.pick(), deck.pick()),
new Player("중수", deck.pick(), deck.pick()),
new Player("하수", deck.pick(), deck.pick())
};
TreeMap rank = new TreeMap(new Comparator() {
public int compare(Object o1, Object o2) {
// (1) 알맞은 코드를 넣어 완성하시오.
}
});
for (int i = 0; i < pArr.length; i++) {
Player p = pArr[i];
rank.put(p, deck.getPoint(p));
System.out.println(p + " " + deck.getPoint(p));
}
System.out.println();
System.out.println("1위는 " + rank.firstKey() + "입니다.");
}
}
class SutdaDeck {
final int CARD_NUM = 20;
SutdaCard[] cards = new SutdaCard[CARD_NUM];
int pos = 0; // 다음에 가져올 카드의 위치
HashMap jokbo = new HashMap(); // 족보를 저장할 HashMap
SutdaDeck() {
for (int i = 0; i < cards.length; i++) {
int num = i % 10 + 1;
boolean isKwang = i < 10 && (num == 1 || num == 3 || num == 8);
cards[i] = new SutdaCard(num, isKwang);
}
registerJokbo(); // 족보 등록
}
void registerJokbo() {
jokbo.put("KK", 4000);
jokbo.put("1010", 3100);
jokbo.put("99", 3090);
jokbo.put("88", 3080);
jokbo.put("77", 3070);
jokbo.put("66", 3060);
jokbo.put("55", 3050);
jokbo.put("44", 3040);
jokbo.put("33", 3030);
jokbo.put("22", 3020);
jokbo.put("11", 3010);
jokbo.put("12", 2060);
jokbo.put("21", 2060);
jokbo.put("14", 2050);
jokbo.put("41", 2050);
jokbo.put("19", 2040);
jokbo.put("91", 2040);
jokbo.put("110", 2030);
jokbo.put("101", 2030);
jokbo.put("104", 2020);
jokbo.put("410", 2020);
jokbo.put("46", 2010);
jokbo.put("64", 2010);
}
int getPoint(Player p) {
if (p == null) return 0;
SutdaCard c1 = p.c1;
SutdaCard c2 = p.c2;
Integer result = 0;
if (c1.isKwang && c2.isKwang) {
result = (Integer) jokbo.get("KK");
} else {
result = (Integer) jokbo.get("" + c1.num + c2.num);
if (result == null) {
result = new Integer((c1.num + c2.num) % 10 + 1000);
}
}
p.point = result.intValue();
return result.intValue();
}
SutdaCard pick() throws Exception {
SutdaCard c = null;
if (0 <= pos && pos < CARD_NUM) {
c = cards[pos];
cards[pos++] = null;
} else {
throw new Exception("남아있는 카드가 없습니다.");
}
return c;
}
void shuffle() {
for (int x = 0; x < CARD_NUM * 2; x++) {
int i = (int) (Math.random() * CARD_NUM);
int j = (int) (Math.random() * CARD_NUM);
SutdaCard tmp = cards[i];
cards[i] = cards[j];
cards[j] = tmp;
}
}
} // SutdaDeck
class Player {
String name;
SutdaCard c1;
SutdaCard c2;
int point;
Player(String name, SutdaCard c1, SutdaCard c2) {
this.name = name;
this.c1 = c1;
this.c2 = c2;
}
public String toString() {
return "[" + name + "] : " + c1.toString() + ", " + c2.toString();
}
} // class Player
class SutdaCard {
int num;
boolean isKwang;
SutdaCard() {
this(1, true);
}
SutdaCard(int num, boolean isKwang) {
this.num = num;
this.isKwang = isKwang;
}
public String toString() {
return num + (isKwang ? "K" : "");
}
}
// [타짜] : 6, 5 1001
// [고수] : 6, 4 2010
// [물주] : 2, 9 1001
// [중수] : 3K, 8K 4000
// [하수] : 4, 5 1009
//
// 1위는 [중수] : 3K, 8K입니다.
나의 답 : 내림차순으로 정렬하려면 기본 정렬 방식의 역(반대, *1)을 반환하거나 비교하는 객체의 위치를 변경하면 된다.
TreeMap rank = new TreeMap(new Comparator() {
public int compare(Object o1, Object o2) {
if (o1 instanceof Player && o2 instanceof Player) {
Player p1 = (Player) o1;
Player p2 = (Player) o2;
return p2.point - p1.point; // 점수를 기준으로 내림차순 정렬
}
return -1;
}
});
[11-14] 다음은 성적처리 프로그램의 일부이다.
Scanner클래스를 이용해서 화면으로부터 데이터를 입력하고 보여주는 기능을 완성하시오.
import java.util.*;
class Exercise11_14 {
static ArrayList record = new ArrayList(); // 성적 데이터를 저장할 공간
static Scanner s = new Scanner(System.in);
public static void main(String args[]) {
while(true) {
switch (displayMenu()) {
case 1:
inputRecord();
break;
case 2:
displayRecord();
break;
case 3:
System.out.println("프로그램을 종료합니다.");
System.exit(0);
}
}
}
// menu를 보여주는 메서드
static int displayMenu() {
System.out.println("**************************************************");
System.out.println("* 성적 관리 프로그램 *");
System.out.println("**************************************************");
System.out.println("1. 학생 성적 입력하기");
System.out.println("2. 학생 성적 보기");
System.out.println("3. 프로그램 종료");
System.out.println();
System.out.print("원하는 메뉴를 선택하세요.(1~3) : ");
int menu = 0;
/*
(1) 아래의 로직에 맞게 코드를 작성하시오.
1. 화면으로부터 메뉴를 입력받는다. 메뉴의 값은 1~3사이의 값이어야 한다.
2. 1~3사이의 값을 입력받지 않으면, 메뉴의 선택이 잘못되었음을 알려주고 다시 입력받는다.
(유효한 값을 입력받을 때까지 반복해서 입력받는다.)
*/
return menu;
}
// 데이터를 입력받는 메서드
static void inputRecord() {
System.out.println("1. 학생 성적 입력하기");
System.out.println("이름, 반, 번호, 국어성적, 영어성적, 수학성적의 순서로 공백없이 입력하세요.");
System.out.println("입력을 마치려면 q를 입력하세요. 메인화면으로 돌아갑니다.");
while (true) {
System.out.print(">>");
/*
(2) 아래의 로직에 맞게 코드를 작성하시오.
1. Scanner를 이용해서 화면으로부터 데이터를 입력받는다. (','를 구분자로)
2. 입력받은 값으로 Student인스턴스를 생성하고 record에 추가한다.
3. 입력받은 값이 q 또는 Q이면 메서드를 종료한다.
4. 입력받은 데이터에서 예외가 발생하면, "입력 오류입니다."를 보여주고 다시 입력받는다.
*/
}
}
// 데이터 목록을 보여주는 메서드
static void displayRecord() {
int koreanTotal = 0;
int englishTotal = 0;
int mathTotal = 0;
int total = 0;
int length = record.size();
if (length > 0) {
System.out.println();
System.out.println("이름 반 번호 국어 영어 수학 총점 평균 전교등수 반등수");
System.out.println("====================================================");
for (int i = 0; i < length; i++) {
Student student = (Student) record.get(i);
System.out.println(student);
koreanTotal += student.kor;
mathTotal += student.math;
englishTotal += student.eng;
total += student.total;
}
System.out.println("====================================================");
System.out.println("총점 : " + koreanTotal + " " + englishTotal + " " + mathTotal + " " + total);
System.out.println();
} else {
System.out.println("====================================================");
System.out.println("데이터가 없습니다.");
System.out.println("====================================================");
}
}
}
class Student implements Comparable {
String name;
int ban, no;
int kor, eng, math;
int total;
int schoolRank;
int classRank; // 반등수
Student(String name, int ban, int no, int kor, int eng, int math) {
this.name = name;
this.ban = ban;
this.no = no;
this.kor = kor;
this.eng = eng;
this.math = math;
total = kor + eng + math;
}
int getTotal() {
return total;
}
float getAverage() {
return (int) ((getTotal() / 3f) * 10 + 0.5) / 10f;
}
public int compareTo(Object o) {
if (o instanceof Student) {
Student tmp = (Student) o;
return tmp.total - this.total;
} else {
return -1;
}
}
public String toString() {
return name + ", " + ban + ", " + no + ", " + kor + ", " + eng + " ," + math + ", "
+ getTotal() + ", " + getAverage() + ", " + schoolRank + ", " + classRank;
}
}
// **************************************************
// * 성적 관리 프로그램 *
// **************************************************
// 1. 학생 성적 입력하기
// 2. 학생 성적 보기
// 3. 프로그램 종료
//
// 원하는 메뉴를 선택하세요.(1~3) : 5
// 유효하지 않은 메뉴를 선택하셨습니다. 다시 입력 바랍니다.
// 원하는 메뉴를 선택하세요.(1~3) : 2
// ====================================================
// 데이터가 없습니다.
// ====================================================
// **************************************************
// * 성적 관리 프로그램 *
// **************************************************
// 1. 학생 성적 입력하기
// 2. 학생 성적 보기
// 3. 프로그램 종료
//
// 원하는 메뉴를 선택하세요.(1~3) : 1
// 1. 학생 성적 입력하기
// 이름, 반, 번호, 국어성적, 영어성적, 수학성적의 순서로 공백없이 입력하세요.
// 입력을 마치려면 q를 입력하세요. 메인화면으로 돌아갑니다.
// >>
// 입력 오류입니다. 다시 입력 바랍니다.
// 이름, 반, 번호, 국어성적, 영어성적, 수학성적의 순서로 공백없이 입력하세요.
// >>자바짱,1,1,100,100,100
// 입력 성공. 입력을 마치려면 q 또는 Q를 입력하세요.
// >>김자바,1,2,80,80,80
// 입력 성공. 입력을 마치려면 q 또는 Q를 입력하세요.
// >>q
// **************************************************
// * 성적 관리 프로그램 *
// **************************************************
// 1. 학생 성적 입력하기
// 2. 학생 성적 보기
// 3. 프로그램 종료
//
// 원하는 메뉴를 선택하세요.(1~3) : 2
//
// 이름 반 번호 국어 영어 수학 총점 평균 전교등수 반등수
// ====================================================
// 자바짱, 1, 1, 100, 100 ,100, 300, 100.0, 0, 0
// 김자바, 1, 2, 80, 80 ,80, 240, 80.0, 0, 0
// ====================================================
// 총점 : 180 180 180 540
//
// **************************************************
// * 성적 관리 프로그램 *
// **************************************************
// 1. 학생 성적 입력하기
// 2. 학생 성적 보기
// 3. 프로그램 종료
//
// 원하는 메뉴를 선택하세요.(1~3) : 3
// 프로그램을 종료합니다.
나의 답 : inputRecord()는 해설을 본 후 생각을 정리했다.
// menu를 보여주는 메서드
static int displayMenu() {
// 생략
int menu = 0;
while(true) {
try {
menu = Integer.parseInt(s.nextLine().trim());
// menu = s.nextInt(); // 사용자가 문자열 or 문자를 입력했을 때 에러 발생
// 1. 화면으로부터 메뉴를 입력받는다. 메뉴의 값은 1~3사이의 값이어야 한다.
if (1 <= menu && menu <= 3) {
break;
} else {
throw new Exception();
}
} catch (Exception e) {
// 2. 1~3사이의 값을 입력받지 않으면, 메뉴의 선택이 잘못되었음을 알려주고 다시 입력받는다.
// (유효한 값을 입력받을 때까지 반복해서 입력받는다.)
System.out.println("유효하지 않은 메뉴를 선택하셨습니다. 다시 입력 바랍니다.");
System.out.print("원하는 메뉴를 선택하세요.(1~3) : ");
}
}
return menu;
}
// 데이터를 입력받는 메서드
static void inputRecord() {
// 생략
while (true) {
System.out.print(">>");
try {
String input = s.nextLine().trim();
if (!input.equalsIgnoreCase("q")) {
// 1. Scanner를 이용해서 화면으로부터 데이터를 입력받는다. (','를 구분자로)
Scanner ss = new Scanner(input).useDelimiter(","); // 구분자
// 2. 입력받은 값으로 Student인스턴스를 생성하고 record에 추가한다.
record.add(new Student(ss.next(), ss.nextInt(), ss.nextInt(), ss.nextInt(), ss.nextInt(), ss.nextInt()));
System.out.println("입력 성공. 입력을 마치려면 q 또는 Q를 입력하세요.");
} else {
// 3. 입력받은 값이 q 또는 Q이면 메서드를 종료한다.
return;
}
} catch (Exception e) {
// 4. 입력받은 데이터에서 예외가 발생하면, "입력 오류입니다."를 보여주고 다시 입력받는다.
System.out.println("입력 오류입니다. 다시 입력 바랍니다.");
System.out.println("이름, 반, 번호, 국어성적, 영어성적, 수학성적의 순서로 공백없이 입력하세요.");
}
}
}1) displayMenu() : 사용자로부터 메뉴를 입력받는다.
* while문(무한 반복문)을 사용하여 사용자가 유효한 값(1~3)을 입력할 때까지 반복해서 입력받는다.
* nextLine()를 이용하여 라인 단위로 입력받은 데이터에 trim()를 사용하여 공백을 제거한다.
nextInt()로 정수를 입력받으면 형변환 할 필요가 없지만, 사용자가 문자열 or 문자를 입력하면 에러가 발생한다.
* 유효한 값(1~3)을 입력하지 않았을 경우 Exception예외를 발생시켜 catch블럭으로 처리한다(다시 입력받음)
2) inputRecord() : 사용자로부터 성적을 입력받아 record(ArrayList)에 저장한다.
2-1) Scanner를 한번 더 생성하여 라인 단위로 입력받은 데이터를 구분자(,)로 다시 나눈다.
처음에는 input으로 데이터를 입력 받았는데 왜 또 Student인스턴스에 데이터를 넣을 때 왜 다시 입력받지? 라는 생각에 갇혔다가 깨달음을 얻게 되었다. 라인 단위로 입력받은 input으로 Scanner를 생성하여 각각 Student인스턴스 타입에 맞게 읽어온 것(ex. 파일) ① 공백 없이 입력받은 데이터를 input에 저장 ② 이를 Scanner로 읽어와 구분자(,)로 나눠 Student인스턴스에 저장
2-2) Student인스턴스를 생성하여 읽어 온 name, ban, no, kor, eng, math(성적)를 record에 추가한다.
2-3) while문(무한 반복문)을 사용하여 사용자가 q나 Q를 입력할 때까지 반복해서 성적을 입력 받는다.
2-4) 입력받은 데이터에서 예외가 발생하면 다시 입력받는다.
'Java의 정석 : 3rd Edition' 카테고리의 다른 글
| [Java의 정석 - 연습문제] Chapter13. 쓰레드(thread) (0) | 2023.06.05 |
|---|---|
| [Java의 정석 - 연습문제] Chapter12. 지네릭스, 열거형, 애너테이션 (0) | 2023.05.31 |
| [Java의 정석 - 연습문제] Chapter10. 날짜와 시간 & 형식화 (0) | 2023.05.11 |
| [Java의 정석 - 연습문제] Chapter09. java.lang패키지와 유용한 클래스 (0) | 2023.02.06 |
| [Java의 정석 - 연습문제] Chapter08. 예외처리 (2) | 2023.01.10 |